Le nuove tecnologie digitali viste dal mondo accademico
*dall'ultima "Emerging technology review" a cura della Stanford University
Le tecnologie emergenti stanno trasformando le società, le economie e la geopolitica. Questa fase è portatrice di promesse ineguagliabili e di rischi inediti. In qualsiasi epoca, i progressi tecnologici favoriscono i paesi che ne sono artefici e propulsori, contribuendo a salvare vite, vincere guerre, diffondere la prosperità e migliorare la condizione umana. Allo stesso tempo, la storia è ricca di esempi di governi ingessati che hanno soffocato l’innovazione con buona pace delle intenzioni di tanti policy makers, e di attori nefasti che hanno sfruttato i progressi tecnologici come i loro fautori non avrebbero mai immaginato. La tecnologia è uno strumento. Non è intrinsecamente buona o cattiva. Ma l’uso che se ne fa può potenziare il talento umano o degradarlo, elevare le società o reprimerle, risolvere sfide difficili o esacerbarle. Questi effetti sono talvolta intenzionali, ma spesso accidentali.
La posta in gioco degli odierni sviluppi tecnologici è particolarmente alta. L’intelligenza artificiale sta già rivoluzionando interi settori, dalla musica alla medicina alle forze armate: il suo impatto è stato paragonato all’invenzione dell’elettricità. Tuttavia, l’IA è solo una delle tante tecnologie che stanno introducendo profondi cambiamenti. In ambiti come la biologia di sintesi, la scienza dei materiali e le neuroscienze c’è il potenziale per enormi progressi a livello di assistenza sanitaria, sostenibilità ambientale, crescita economica e non solo. Abbiamo già vissuto fasi di grandi cambiamenti tecnologici in passato. Ma non abbiamo mai assistito alla convergenza di così tante tecnologie dotate del potenziale di cambiare così tante cose, e così velocemente.

COME GESTIRE LE SFIDE MULTIPLE DELL’AI. La nostra analisi muove da alcune considerazioni. La prima è che i policy makers necessitano di migliori risorse per comprendere gli sviluppi tecnologici in modo più semplice, veloce e fluido. La politica tecnologica richiede conoscenze più sofisticate in una vasta gamma di ambiti e settori. In effetti, oggi la categoria dei policy makers abbraccia una sempre più ampia rosa di decision makers, da deputati e funzionari del ramo esecutivo ai governi statali e locali, fino agli investitori e ai manager d’azienda. Sin troppo spesso i leader governativi non dispongono delle competenze tecniche per comprendere le evoluzioni scientifiche, mentre ai tecnologi mancano le competenze politiche per valutare e integrare considerazioni di tipo sociale, come quelle relative alla sicurezza (intesa anche come incolumità delle persone), nella concezione dei prodotti. Tra i punti chiave di questo report, per esempio, ci sono alcuni dati di fatto che possono apparire sorprendenti o persino controintuitivi ai non addetti ai lavori: L’IA ha ricevuto grande attenzione mediatica, ma in definitiva le biotecnologie hanno un potenziale di trasformazione della società pari a quello dei sistemi computazionali. Le tecnologie spaziali, inoltre, sono sempre più importanti nella vita di tutti i giorni, dalla navigazione GPS ai servizi bancari. Eppure lo spazio è una risorsa planetaria sempre più congestionata e contesa, con migliaia di nuovi satelliti commerciali e milioni di detriti che potrebbero compromettere l’accesso a questi beni comuni globali.
La sfida più decisiva ai fini dell’energia sostenibile riguarda, invece, l’ordine di grandezza; per fornire 72 ore di energia di riserva al pianeta occorre l’equivalente di due secoli di produzione di batterie agli ioni di litio: Le criptovalute, infine, non sono l’aspetto più importante della crittografia attuale e non sono sinonimo di blockchain (che ha applicazioni di ampia portata).
Come suggeriscono questi esempi, i policy makers hanno bisogno di risorse migliori e di facile accesso per comprendere le basi tecnologiche e le nuove scoperte prima che si manifestino criticità, per concentrare la loro attenzione sulle questioni prioritarie, per valutare meglio le implicazioni politiche, per guardare oltre l’orizzonte al fine di plasmare, accelerare e guidare l’innovazione insieme alle applicazioni tecnologiche future. Serve un nuovo modello di formazione tecnologica per i leader politici. Questo report vuole essere un primo importante passo in tale direzione.
La seconda considerazione è che la leadership americana nell’innovazione globale è importante non solo per l’economia e la sicurezza nazionale: è la chiave di volta per preservare un ecosistema tecnologico globale dinamico e per trarne tutti i benefici.
La collaborazione scientifica internazionale è sempre stata fondamentale per promuovere la pace, il progresso e la prosperità globali, anche in tempi di intensa competizione geopolitica. Durante la guerra fredda, per esempio, i politici e gli scienziati nucleari americani e sovietici hanno collaborato per ridurre il rischio di una guerra nucleare accidentale mediante accordi sul controllo degli armamenti e apposite misure di sicurezza. Oggi l’ascesa della Cina pone molte sfide inedite. Tuttavia, preservare un solido ecosistema globale di cooperazione scientifica resta fondamentale – e non è qualcosa che si fa con la bacchetta magica. Per garantire l’apertura necessaria alla scoperta scientifica servono lavoro, leadership e un impegno fondamentale per la libertà. La libertà è il terreno fertile dell’innovazione e assume molte forme: la libertà di criticare un governo, di riconoscere il fallimento di un programma di ricerca come leva di progresso, di condividere apertamente le scoperte con altri soggetti, di collaborare al di là dei confini tecnici e geografici con reciproco accesso a talenti, conoscenze e risorse e di lavorare senza timore di repressioni o persecuzioni. Insomma, c’è una differenza sostanziale tra un ecosistema dell’innovazione guidato da una democrazia o da un’autocrazia. Gli Stati Uniti hanno i loro difetti e le loro sfide da affrontare, ma restano il miglior garante della libertà scientifica a livello globale.
Il terzo punto da considerare è che il ruolo del mondo accademico nell’innovazione è essenziale ma sempre più a rischio. L’ecosistema dell’innovazione statunitense si basa su tre pilastri: governo, settore privato e mondo accademico. Perché abbia successo, tutti e tre devono mantenersi solidi e attivamente impegnati. Nel corso della storia, le università americane hanno prodotto scoperte scientifiche rivoluzionarie, dall’invenzione del vaccino antipoliomelite al propellente per i razzi. Le università sono state anche terreno di coltura di innovazioni politiche, dalla teoria della deterrenza nucleare all’economia comportamentale. E hanno svolto un ruolo decisivo nella formazione delle nuove generazioni.
Oggi, tuttavia, le innovazioni emergono sempre più dal settore privato, spesso affiancato dal mondo accademico. Anche le fonti di finanziamento dell’innovazione sono cambiate – e in modo molto preoccupante. Il governo degli Stati Uniti è l’unico finanziatore in grado di effettuare grandi e rischiosi investimenti nella scienza di base condotta nelle università (e nei laboratori nazionali), essenziale per le applicazioni future. Tuttavia, i finanziamenti federali per la ricerca e lo sviluppo sono crollati dagli anni Sessanta, passando dall’1,86% del PIL nel 1964 ad appena lo 0,66% nel 20161. Gli investimenti del settore privato nelle aziende tecnologiche e nella ricerca universitaria sono aumentati in misura sostanziale, ma non bastano a colmare la lacuna; il finanziamento federale della ricerca universitaria permette di studiare sfide e opportunità tecnologiche diverse rispetto ai finanziamenti privati. Per citare la conclusione di un report della task force sull’innovazione del Council on Foreign Relations, “la leadership degli Stati Uniti nella scienza e nella tecnologia è a rischio a causa di una stagnazione pluridecennale del sostegno e dei finanziamenti federali per la ricerca e lo sviluppo. Gli investimenti del settore privato sono aumentati, ma non possono sostituire le attività di R&D finanziate a livello federale e mirate su interessi economici, strategici e sociali nazionali”.
Certo, la crescente influenza dell’industria privata nell’innovazione porta benefici significativi. Ma sta anche generando rischi gravi e più subdoli per la salute dell’intero ecosistema dell’innovazione americano. Università e aziende non sono la stessa cosa. Le aziende devono rispondere a investitori e azionisti che si aspettano un ritorno dai loro investimenti, per cui tendono a concentrarsi su tecnologie che possano essere commercializzate nell’immediato futuro. Le università operano invece su orizzonti temporali molto più lunghi, senza badare al profitto, impegnandosi in quella ricerca fondamentale alle frontiere della conoscenza che offre pochi o nessun beneficio commerciale prevedibile. E che è alla base di applicazioni future le quali possono richiedere anni, o addirittura decenni, per emergere. Il “successo immediato” del vaccino contro il covid nel 2021, per esempio, è stato il risultato di trent’anni di ricerca universitaria. Allo stesso modo, ci sono voluti decenni di ricerca nella teoria dei numeri, una branca della matematica pura, per sviluppare la moderna crittografia, ampiamente utilizzata per la protezione dei dati.
Oggi la tecnologia e i talenti stanno migrando dal mondo accademico al settore privato, accelerando lo sviluppo di prodotti commerciali, ma al tempo stesso erodendo le basi del futuro. Stiamo già raggiungendo un punto di non ritorno nell’IA. Nel 2020, due terzi degli studenti che hanno conseguito un dottorato di ricerca in IA nelle università statunitensi hanno trovato lavoro nel privato, assottigliando così il fronte dei docenti che insegneranno alla prossima generazione2. Solo una manciata di aziende tra i colossi globali dispone dei talenti e dell’enorme potenza di calcolo necessari per sviluppare grandi e sofisticati modelli linguistici come GPT-4. Nessuna università si avvicina a quello standard.
Tali tendenze hanno diverse preoccupanti implicazioni. Una su tutte: la ricerca in questo campo sarà probabilmente orientata verso applicazioni che rispondono a interessi commerciali anziché pubblici. La possibilità per le università – o per qualsiasi altro soggetto al di fuori delle aziende leader dell’IA – di condurre analisi indipendenti delle carenze, dei rischi e delle vulnerabilità dell’IA (in particolare dei grandi modelli linguistici noti alle recenti cronache) diventerà più importante e al tempo stesso più ardua. Inoltre, più l’industria offre concentrazioni senza pari di talenti, potenza di calcolo, dati di addestramento e modelli ultrasofisticati, più è probabile che le future generazioni di cervelli dell’IA continuino a riversarvisi, svuotando le facoltà universitarie e compromettendo la capacità nazionale di guidare la ricerca – intesa come ricerca di base e ad ampio raggio – in questo settore.
I CONTORNI DELL’INTELLIGENZA ARTIFICIALE: CAPIRE PER CONTROLLARE. L’IA promette di essere un fattore fondamentale di sviluppo tecnologico in molti campi, probabilmente di importanza paragonabile all’avvento dell’elettricità o, per restare in epoca più recente, di internet. La scienza computazionale, con la disponibilità globale di reti e i dati di un’intera civiltà (tutto ciò che è alla base dell’IA di oggi e di domani), lascia presagire un impatto analogo sul progresso tecnologico. Inoltre, gli utenti dell’IA non saranno solo individui con una formazione specialistica: l’uomo della strada interagirà direttamente con sofisticate applicazioni per tutta una serie di attività quotidiane.
Il mercato globale dell’IA ha raggiunto un valore di 136,55 miliardi di dollari nel 2022, con il Nord America che ha assorbito il 36,8% del fatturato complessivo. Secondo uno studio dell’Università di Stanford, il totale degli investimenti privati nell’IA ha superato i 93 miliardi di dollari nel 2021, con un raddoppio dei capitali rispetto al 20203. Mentre le start-up dell’IA hanno ricevuto negli ultimi anni circa il 9-10% degli investimenti in venture capital a livello globale4, i finanziamenti complessivi alle stesse start-up hanno subito un notevole rallentamento nel 2022, scendendo da un massimo storico di circa 18 miliardi di dollari nel terzo trimestre del 2021 a circa 8,3 miliardi di dollari nel terzo trimestre dell’anno successivo5. Secondo le stime di Goldman Sachs, l’IA generativa farà aumentare il PIL mondiale di 7.000 miliardi di dollari e la crescita della produttività dell’1,5% nell’arco di dieci anni, se adottata su larga scala.
Tuttora si discute su quali siano i sottocampi dell’IA, anche perché i loro confini sono spesso fluidi. Ne elenchiamo alcuni tra i principali. La computer vision, che consente alle macchine di riconoscere e comprendere informazioni visive dal mondo reale, convertirle in dati digitali e prendere decisioni basandosi su di essi; il machine learning, che consente ai computer di eseguire compiti senza istruzioni esplicite, spesso generalizzando i pattern nei dati; il deep learning, che ne è un derivato e si basa su reti neurali artificiali multistrato per modellare e comprendere relazioni complesse all’interno dei dati; il Natural Language Processing (NLP) o elaborazione del linguaggio naturale, che dota le macchine della capacità di comprendere, interpretare e produrre enunciati orali e testi scritti.
L’odierna IA si basa, poi, prevalentemente sul machine learning, pur attingendo anche ad altri sottocampi. Il machine learning richiede dati e potenza di calcolo, nota anche come compute6, e gran parte dell’attuale ricerca sull’IA presuppone l’accesso a tali risorse su enorme scala.
L’IA richiede grandi quantità di dati come fonte di apprendimento. Questi dati possono essere di varia natura: testi, immagini, video, letture di sensori e altro ancora. La qualità e la quantità dei dati svolgono un ruolo fondamentale nel determinare le prestazioni e le capacità dei modelli IA. Senza dati sufficienti e di alta qualità, i modelli possono generare risultati imprecisi o distorti. In parole povere, un modello viene sviluppato per risolvere un particolare problema; problemi diversi richiedono modelli diversi e se le differenze superano un certo limite occorre sviluppare modelli completamente nuovi. È tuttora in corso la ricerca su come addestrare i modelli in modo incrementale, partendo da un modello esistente e utilizzando poi una quantità molto più ridotta di dati appositamente selezionati per affinarne le prestazioni in funzione di obiettivi specifici.
Per avere un’idea degli ordini di grandezza, prendiamo un modello IA recentemente balzato agli onori delle cronache, GPT-4. Le stime sui dati necessari per addestrarlo parlano di circa un milione di libri (centinaia di gigabyte di testo) estratti da miliardi di pagine web e documenti scansionati. Anche i requisiti hardware per la potenza di calcolo sono notevoli. I costi per supportare l’addestramento di GPT-4, infatti, sono stati enormi. Secondo alcuni resoconti, l’operazione ha richiesto circa 25.000 chip di deep learning con GPU Nvidia A100, al costo di 10.000 dollari l’uno, ed è durata circa cento giorni7. Tirando le somme e considerando che probabilmente sono stati necessari anche altri componenti fisici, i costi hardware complessivi per GPT-4 sono quantificabili in almeno qualche centinaio di milioni di dollari. E parliamo di un hardware basato su chip speciali generalmente prodotti al di fuori degli Stati Uniti8.
Infine, l’addestramento dei modelli IA è un’attività ad alto dispendio energetico. Una stima dei costi di elettricità per addestrare un modello linguistico di grandi dimensioni come GPT-4 si aggira sui 50 milioni di kilowattora. Una volta che la macchina è in funzione, poi, il costo energetico di una query su ChatGPT è di circa 0,002 kilowattora9. Considerando centinaia di milioni di query al giorno, il costo energetico operativo di ChatGPT potrebbe essere di qualche centinaio di migliaia di kilowattora, ovvero di decine di migliaia di dollari al giorno.
L’IA può automatizzare un’ampia gamma di compiti. Ma è anche particolarmente promettente per il potenziamento delle capacità umane e la facilitazione delle attività che all’uomo riescono meglio10. I sistemi IA possono affiancare gli esseri umani, integrandoli e assistendoli invece di sostituirli.
In questo ambito, i modelli linguistici di grandi dimensioni hanno attirato notevole attenzione in virtù della loro estrema sofisticatezza. In effetti, le loro capacità hanno portato più d’uno a suggerire che i LLM siano le prime scintille dell’intelligenza artificiale generale (AGI)11. L’AGI è un’intelligenza artificiale in grado di eseguire qualsiasi compito intellettuale di cui un essere umano è capace, a partire dall’apprendimento. Ma essendo supportata da un computer, è probabile che apprenda molto più velocemente degli esseri umani, surclassandoli in breve tempo.
UNA MAPPATURA DEI RISCHI. La prospettiva di un prossimo avvento dell’intelligenza artificiale generale ha suscitato un grande dibattito sui relativi rischi. Nel maggio del 2023, alcuni autorevoli esperti del settore hanno rilasciato una dichiarazione in cui affermano che “la mitigazione del rischio di estinzione derivante dall’IA dovrebbe essere una priorità globale, al pari di altri rischi su scala sociale, come le pandemie e la guerra nucleare”. Preoccupati per la velocità di aumento di potenza dei sistemi basati sull’IA, costoro temono che, in assenza di una buona governance, i sistemi futuri possano porre dei rischi esistenziali per l’umanità.
Altri suggeriscono che concentrarsi su scenari apocalittici poco probabili distragga dai rischi reali e immediati che l’IA pone in questo momento12. A loro dire, i ricercatori nel campo dell’IA dovrebbero affrontare in via prioritaria i danni che questi sistemi stanno già causando, a partire dalle distorsioni dei processi decisionali e dalla soppressione di posti di lavoro. Sono questi i problemi su cui i governi e le autorità di controllo dovrebbero focalizzare i loro sforzi.
Allo stato attuale, i modelli IA come GPT-4 possono essere sviluppati solo da importanti realtà industriali che dispongono delle risorse necessarie per costruire e gestire grandi centri di calcolo e dati, come Google, Microsoft e Meta (in precedenza Facebook). Gli accademici e altri tradizionali attori della società civile hanno intrapreso ricerche per comprendere le potenziali ripercussioni sociali dell’IA, ma con le grandi aziende che controllano l’accesso a questi sistemi, non possono operare in modo indipendente.
Per questo motivo, nel luglio 2023 un gruppo bipartisan di deputati statunitensi ha proposto un disegno di legge per istituire la National Artificial Intelligence Research Resource (NAIRR), un’infrastruttura di ricerca nazionale condivisa che fornisca un più ampio accesso a quel complesso insieme di risorse, dati e strumenti necessari per sostenere la ricerca su un’IA sicura e affidabile. Tuttavia, l’entità delle risorse governative proposte è notevolmente inferiore (di 5 o addirittura 10 volte) a quanto il settore privato può e vuole investire.
Spesso le nuove tecnologie hanno impatti sia positivi sia negativi. I potenziali impatti positivi dell’IA si riscontrano soprattutto nelle applicazioni al servizio della società. Per esempio, i camionisti possono affidare all’IA le fasi più noiose e dispendiose di tempo del loro lavoro – la guida su lunghe distanze – pur continuando a occuparsi di quelle che richiedono interazioni umane, solitamente coincidenti con i primi e gli ultimi chilometri dei loro tragitti. I sensori e le telecamere smart, invece, possono migliorare la sicurezza dei pazienti nelle unità di terapia intensiva, nelle sale operatorie e persino a casa, assicurando agli operatori sanitari e a chi assiste i malati una maggiore capacità di monitorare e gestire l’evoluzione delle loro condizioni di salute (lesioni e cadute comprese).
I potenziali impatti negativi dell’IA emergeranno probabilmente dai problemi già noti e dal suo incontrastato successo futuro. Vediamo alcuni punti critici dei principali modelli IA attualmente disponibili. Il primo è l’esplicabilità cioè la capacità di spiegare il ragionamento e descrivere i dati alla base delle conclusioni di un sistema IA. L’esplicabilità è utile per dare fiducia agli utenti sul buon funzionamento di un sistema IA; tutelarsi da bias di vario genere; conformarsi a standard normativi o indirizzi programmatici; aiutare gli sviluppatori a capire perché un sistema funziona in un certo modo, a valutare le sue vulnerabilità o a verificarne i risultati; soddisfare le aspettative della società sulla partecipazione degli individui al processo decisionale. L’odierna IA è molto spesso incapace di spiegare le basi su cui poggia una certa conclusione. Le spiegazioni non sono sempre necessarie, ma in alcuni casi, come quello delle decisioni mediche, possono risultare essenziali.
Un altro punto critico riguarda bias e correttezza: poiché i modelli di apprendimento automatico vengono addestrati su insiemi di dati esistenti, è probabile che assimilino eventuali pregiudizi presenti in quegli insiemi di dati. Per bias si intende, in questo caso, una proprietà dei dati generalmente considerata indesiderabile a livello sociale. Per esempio, se un sistema di riconoscimento facciale viene addestrato principalmente su immagini di individui appartenenti a un particolare gruppo etnico, la sua accuratezza nell’identificazione di individui appartenenti ad altri gruppi etnici può essere limitata. L’uso di un sistema simile potrebbe facilmente determinare incongruenze nell’identificazione di individui appartenenti agli altri gruppi. Se è vero che gli insiemi di dati riflettono la nostra storia, rifletteranno anche i bias che vi si annidano, e un modello di apprendimento automatico basato su di essi ne risentirà a sua volta.
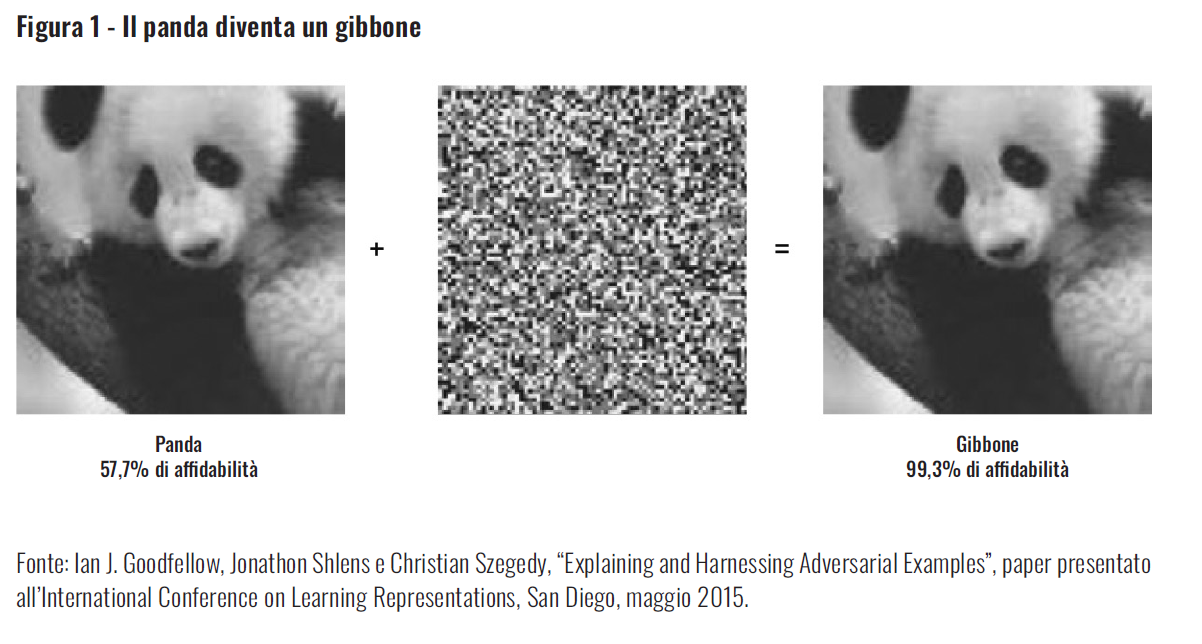
Bisogna poi considerare la vulnerabilità allo spoofing: in molti modelli IA è possibile modificare leggermente i dati in ingresso per portarli volutamente a conclusioni sbagliate. Per esempio, nella figura 1, l’aggiunta di un piccolo elemento di disturbo all’immagine del panda fa sì che questo venga classificato come un gibbone con una percentuale di affidabilità molto elevata. A questo si aggiunge la possibilità di generare contenuti audio e video altamente realistici ma del tutto inautentici (deepfake); tale capacità ha evidenti implicazioni per le prove presentate in tribunale e per certa ingannevole propaganda politica.
Le allucinazioni dell’IA si riferiscono, invece, a quelle situazioni in cui un modello genera risultati o risposte plausibili, ma che non corrispondono alla realtà. In altre parole, i modelli IA possono benissimo inventare di sana pianta. I risultati sono plausibili perché costruiti sulla base di pattern statistici che il modello ha imparato a riconoscere grazie ai dati di addestramento. Ma potrebbero non essere veritieri, perché il modello non ha conoscenza del mondo reale.
Per quanto riguarda la privacy, inoltre, è importante notare che molti LLM sono addestrati su dati reperiti su internet in modo piuttosto indiscriminato, e tali dati spesso comprendono informazioni personali individuali. Se integrate in tali modelli, queste ultime potrebbero essere più esposte alla pubblica visibilità.
Un’altra problematica riguarda l’eccesso di fiducia. Se i sistemi IA diventano una presenza stabile nella società, l’effetto novità per gli utenti verrà inevitabilmente meno. Il livello di fiducia nei prodotti informatici spesso aumenta con la familiarità. Ma un certo scetticismo nei confronti delle risposte fornite da un sistema è indispensabile per verificarne la correttezza. Se la fiducia nell’IA aumenta al diminuire dello scetticismo, c’è un rischio maggiore di trascurare errori e cantonate varie. Secondo un recente esperimento, quanti hanno accesso a un assistente di codifica basato sull’IA scrivono codice molto meno sicuro rispetto a chi non se ne avvale, anche se sono più propensi a credere di aver scritto codice sicuro13.
Ulteriori elementi da considerare riguardano i dati fuori distribuzione e le violazioni di copyright. Tutti i sistemi di apprendimento automatico devono essere addestrati su un grande volume di dati. Se gli input di un sistema sono sostanzialmente diversi dai dati di addestramento – o “out of distribution” – il sistema può trarre conclusioni più inaffidabili rispetto a quelle che si otterrebbero con input simili ai dati di addestramento. Inoltre, bisogna considerare che alcuni modelli basati sull’IA sono stati addestrati su grandi volumi di dati reperiti online. Questi dati vengono generalmente utilizzati senza il consenso o l’autorizzazione dei loro proprietari, il che solleva importanti questioni circa l’adeguato compenso e il riconoscimento della titolarità degli stessi.
I ricercatori nel campo dell’IA sono consapevoli dei problemi come quelli sopra descritti, e in molti casi hanno elaborato o stanno elaborando misure correttive. Bisogna dire però che in genere la portata di tali difese non va molto al di là delle particolari criticità per cui vengono messe in campo.
Tutti questi aspetti pongono importanti sfide di innovazione e di implementazione. La sfida principale legata alla fase operativa dell’innovazione IA è la gestione del rischio. Si dice spesso che l’intelligenza artificiale, e in particolare l’apprendimento automatico, introduce un nuovo paradigma concettuale per cui i sistemi sfruttano le informazioni a proprio vantaggio basandosi sul riconoscimento di modelli (nel senso più ampio del termine), anziché sulla comprensione esplicita di situazioni che hanno una certa probabilità di verificarsi. Trattandosi di una novità, coloro che decidono di impiegare sistemi basati sull’IA non hanno una piena comprensione dei rischi che potrebbero derivarne.
Si pensi, per esempio, all’IA come approccio cruciale per migliorare l’efficacia delle operazioni militari. Nonostante vi sia ampio consenso da parte dei servizi militari e del Dipartimento della Difesa statunitense sui grandi benefici offerti dall’intelligenza artificiale, l’effettiva integrazione delle relative capacità nelle forze armate procede a rilento. Una delle principali ragioni sta nel fatto che il sistema di approvvigionamento del dipartimento della Difesa è stato sostanzialmente concepito per ridurre al minimo le probabilità di fallimento programmatico, frode, iniquità, sprechi e abusi – insomma, per minimizzare i rischi. In questo contesto, non sorprende che gli incentivi a tutti i livelli burocratici siano allineati agli stessi criteri. Perché i nuovi approcci (come l’IA) possano attecchire, probabilmente occorre un maggior grado di accettazione del rischio.
LE SFIDE POLITICHE, LEGALI E NORMATIVE. Modelli linguistici di grandi dimensioni come GPT-4 hanno già hanno già dimostrato di poter essere utilizzati in svariati ambiti, dalla giustizia all’assistenza clienti, dalla scrittura di codice al giornalismo. Il che ha suscitato il timore di un profondo impatto dell’IA sull’occupazione, e in particolare sui cosiddetti lavori della conoscenza. Ma si naviga nell’incertezza. Quali e quanti posti di lavoro spariranno o saranno creati? Quali compiti potranno essere meglio gestiti dall’IA?
Alcune tendenze e linee generali sono evidenti. Coloro che svolgono lavori impiegatizi di routine potranno essere più penalizzati rispetto a chi ricopre mansioni che richiedono uno sforzo fisico; per alcuni ci saranno dolorosi cambiamenti nel breve termine14. L’IA, inoltre, sta contribuendo in certi casi ad aumentare la produttività dei lavoratori e la soddisfazione sul lavoro15. Ma c’è anche chi sta perdendo il posto perché l’intelligenza artificiale – benché potenzialmente meno performante degli esseri umani – dimostra una competenza adeguata a certe mansioni aziendali16.
Infine, è importante notare come la formazione dei lavoratori che hanno perso l’impiego per renderli più competitivi in un’economia basata sull’IA non sia in grado di risolvere il problema, in assenza di nuovi posti di lavoro. La natura e la portata delle nuove occupazioni figlie della diffusione dell’IA non sono al momento chiare, anche se storicamente l’innovazione tecnologica non ha comportato una perdita netta di posti di lavoro nel lungo periodo.
Tali sfide hanno posto sul tavolo dei decisori politici la questione della regolamentazione dell’intelligenza artificiale, con i governi di tutto il mondo sempre più dediti all’introduzione di regolamenti e linee guida. La ricerca sulle tecnologie fondamentali dell’IA è difficile – se non impossibile – da regolamentare, soprattutto se ci sono altre nazioni fortemente incentivate ad andare avanti a prescindere dalle iniziative dei policy makers statunitensi. Lo stesso vale per le restrizioni volontarie alla ricerca da parte di aziende preoccupate per la concorrenza. La regolamentazione di specifiche applicazioni di IA può essere più facile da implementare, anche in virtù dei quadri normativi esistenti in settori applicativi come l’assistenza sanitaria, la finanza e la giustizia.
L’UE sta promuovendo una legislazione completa che fornisca regole armonizzate per la governance dell’intelligenza artificiale, al fine di mitigare nuovi rischi o conseguenze negative per gli individui o la società. Negli Stati Uniti, da discussioni più recenti a livello federale e statale sono nate idee come la creazione di un’agenzia centralizzata per l’IA, la concessione di licenze alle aziende del settore e gli obblighi di registrazione e trasparenza per i nuovi modelli di intelligenza artificiale17. Resta da vedere se gli sforzi normativi risulteranno poi coerenti con la realtà tecnica.
Un’altra questione centrale riguarda la sicurezza nazionale. Si prevede, infatti, che l’IA avrà un profondo impatto sulle forze armate18. I sistemi d’arma, il comando e controllo, la logistica, l’approvvigionamento e l’addestramento sfrutteranno diverse tecnologie IA per operare in modo più efficace ed efficiente, a costi inferiori e con minori rischi per le forze amiche. Il dipartimento della Difesa statunitense sta destinando miliardi di dollari alle riforme istituzionali e alla promozione della ricerca per integrare l’intelligenza artificiale nelle strategie di preparazione e gestione dei conflitti. Le autorità militari riconoscono che il mancato adattamento alle sfide e alle opportunità emergenti porrebbe rischi significativi per la sicurezza nazionale, soprattutto considerando che sia la Russia sia la Cina stanno investendo massicciamente in capacità IA.
Il dipartimento della Difesa sa anche di dover seguire una certa etica nello sviluppo delle capacità IA, e ha adottato una serie di principi guida che chiamano in causa la responsabilità, l’equità, la tracciabilità, l’affidabilità e la governabilità nell’IA e per l’IA19. Un’altra importante preoccupazione, sottesa a quei principi, ma che vale la pena di richiamare esplicitamente, riguarda l’opportunità o meno dell’applicazione dell’IA a funzioni come il comando e controllo nucleare.
Gli Stati Uniti, inoltre, si stanno giocando il futuro per quanto riguarda il bacino di talenti dell’IA. Docenti di Stanford e di altre università riferiscono che il numero di studenti specializzati che si lanciano nell’industria privata, in particolare nelle start-up, è in aumento a discapito di quelli che scelgono la carriera accademica e danno un contributo alla ricerca di base sull’IA.
Come accennato nelle considerazioni iniziali, sono molti i fattori all’origine di questo trend, a partire dal fatto che le carriere nel privato offrono pacchetti retributivi molto più generosi di quelli del mondo accademico. I ricercatori universitari devono ottenere finanziamenti per potersi permettere apparecchiature e collaboratori come scienziati, tecnici e programmatori, andando a caccia di sovvenzioni pubbliche, generalmente misere rispetto alle somme che le grandi aziende sono disposte a investire per i loro ricercatori. L’industria, inoltre, spesso prende decisioni più velocemente rispetto ai finanziatori pubblici e impone meno regole all’attività di ricerca. Le grandi aziende hanno il vantaggio di disporre di infrastrutture di supporto alla ricerca, come centri di calcolo e archivi di dati.
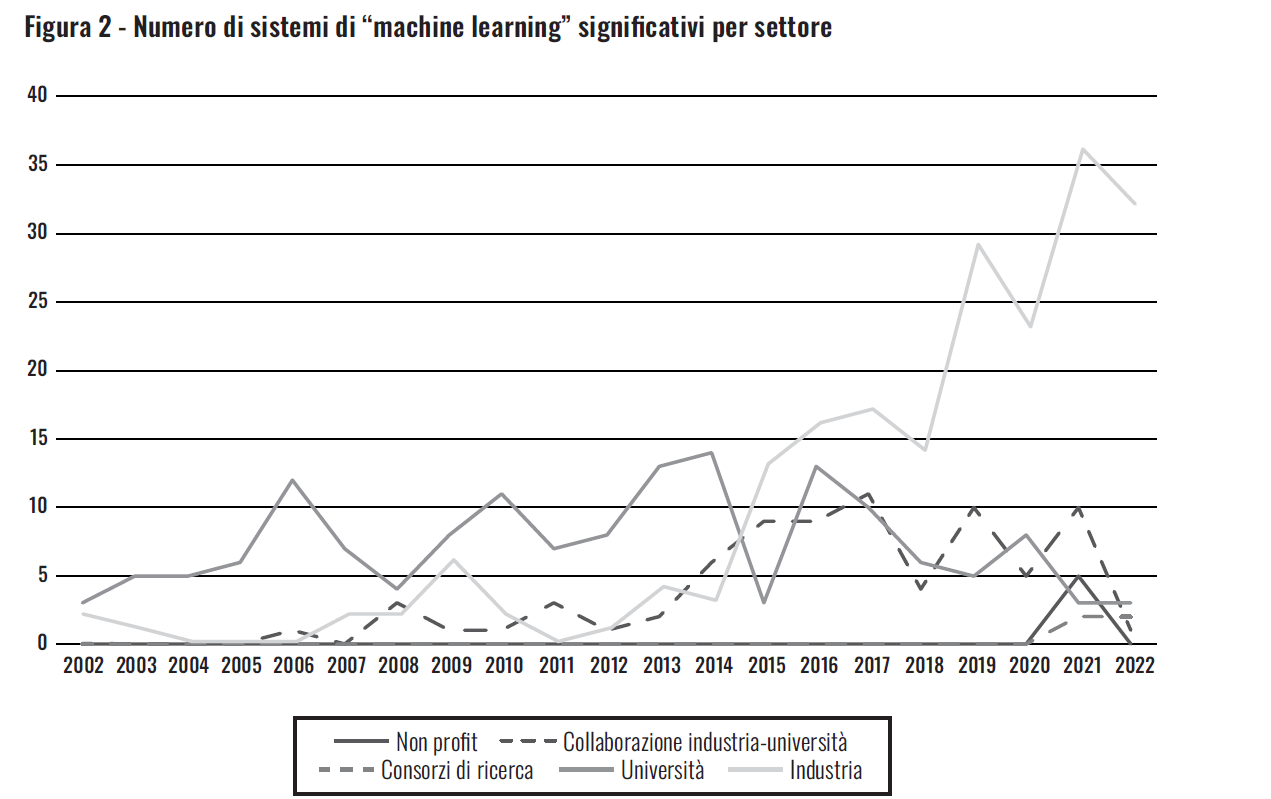
Una conseguenza importante è che il mondo accademico offre un accesso limitato alle infrastrutture di ricerca, per cui gli studenti statunitensi non possono formarsi su sistemi all’avanguardia, almeno non se le loro università non sono collegate a realtà industriali. La figura 2 mostra che la maggior parte dei sistemi di machine learning più significativi oggi è rilasciata dall’industria, e solo una piccolissima percentuale da istituzioni accademiche, consorzi di ricerca o organizzazioni non profit.
Nel frattempo, complici gli sforzi della Cina per attirare i migliori talenti, molti scienziati sono ulteriormente tentati di lasciare gli Stati Uniti. Sebbene tali sforzi siano spesso rivolti ai cinesi residenti negli Stati Uniti (che siano già ben affermati o in procinto di completare gli studi universitari), Pechino offre pacchetti di reclutamento che promettono benefit simili a quelli dell’industria privata: stipendi elevati, lauti finanziamenti alla ricerca e apparente libertà dalla burocrazia. Tutti questi fattori stanno determinando una fuga di cervelli dell’IA che non giova al mondo della ricerca statunitense.
Footnotes:
1 James Manyika e William H. McRaven, Innovation and National Security: Keeping our edge, Independent Task Force Report No. 77, Council on Foreign Relations, 2019.
2 Nur Ahmed, Muntasir Wahed e Neil C. Thompson, “The growing influence of industry in AI research”, Science 379, n. 6635, marzo 2023.
3 Daniel Zhang et al., The AI Index 2022 Report, Institute for Human-Centered AI, Stanford University, marzo 2022.
4 Gené Teare, “Special Series Launch: the promises and perils of a decade of AI funding”, Crunchbase News, 22 novembre 2022.
5 Shubham Sharma, “Report: AI startup funding hits record high of $17.9B in Q3”, VentureBeat, 11 novembre 2021.
6 Jafar Alzubi, Anand Nayyar e Akshi Kumar, “Machine learning from theory to algorithms: an overview”, Journal of Physics: Conference Series 1142, Second National Conference on Computational Intelligence, dicembre 2018.
7 Kif Leswing, “Meet the $10,000 Nvidia chip powering the race for A.I.”, CNBC, 23 febbraio 2023; Kasper Groes Albin Ludvigsen, “The carbon footprint of GPT-4”, Medium, 18 luglio 2023.
8 Darian Woods e Adrian Ma, “The semiconductor founding father”, 21 dicembre 2021, in The Indicator from Planet Money, podcast realizzato da National Public Radio.
9 Kasper Ludvigsen, “ChatGPT’s electricity consumption”, Medium, 12 luglio 2023.
10 Hope Reese, “A human-centered approach to the AI revolution”, Institute for Human-Centered AI, Stanford University, 17 ottobre 2022.
11 Sébastien Bubeck et al., “Sparks of Artificial General Intelligence: early experiments with GPT-4”, arXiv, Cornell University, 13 aprile 2023.
12 Editorial, “Stop talking about tomorrow’s AI doomsday when AI poses risks today”, Nature, n. 618, giugno 2023.
13 Neil Perry et al., “Do users write more insecure code with AI assistants?”, arXiv, Cornell University, 16 dicembre 2022.
14 Claire Cain Miller e Courtney Cox, “In Reversal Because of A.I., office jobs are now more at risk”, New York Times, 24 agosto 2023.
15 Martin Neil Baily, Erik Brynjolfsson e Anton Korinek, “Machines of Mind: the case for an AI-powered productivity boom”, Brookings Institution, 10 maggio 2023.
16 Pranshu Verma e Gerrit De Vynck, “ChatGPT took their jobs: now they walk dogs and fix air conditioners”, Washington Post, 5 giugno 2023.
17 Dylan Matthews, “The AI rules that US policymakers are considering, explained”, Vox, 1 agosto 2023.
18 National Security Commission on Artificial Intelligence, Rapporto finale, 19 marzo 2021.
19 C. Todd Lopez, “DOD adopts 5 principles of Artificial Intelligence ethics”, Dipartimento della Difesa degli Stati Uniti, 25 febbraio 2020.
Questo report della Stanford University, intitolato “The Stanford Emerging Technology Review 2023”, è stato presieduto da Condoleezza Rice, John B. Taylor, Jennifer Widom e Amy Zegart e diretto da Herbert S. Lin.
*Questo articolo è pubblicato sul numero 1-2024 di Aspenia