A business model for digital integration
Though all businesses depend on economies of scale (whether on the supply side or the demand side), learning-by-doing is crucial, particularly to high-tech enterprises. Learning is indeed essential and requires investments in data collection, analysis and testing. And this is where competition between the high tech giants is now taking place, also involving start-ups, as long as they are willing to invest in expertise.
The term “network economies” has a precise and clear economic meaning, yet neoeconomists tend to confuse it with other concepts, such as incremental returns to scale and “learning-by-doing”. This article seeks to clarify the matter.
THE IMPORTANCE OF LEARNING-BY-DOING. Let us consider the following definitions.
Economies of scale – demand-side. The benefit that each subsequent user derives from the enjoyment of a service is greater the more users have already enjoyed it (network economies, network externalities).
Economies of scale – supply side. The incremental production cost of an output (or of an incremental improvement in quality) diminishes as output increases (growing returns to scale).
Learning-by-doing. The unit production cost (or incremental improvement in quality) decreases as output increases (learning curve, or experience curve).
I consider the “demand-side” and “supply-side” definitions of economies of scale extremely useful, because they immediately highlight the virtuous mechanism that generates the phenomenon. Network economies depend on enhanced value based on the number of units sold, whereas returns to scale are based on cost reductions or improvements in quality in relation to the number of units produced.
The difference between economies of scale on the supply side and learning-by-doing has to do with timing: learning-by-doing is usually defined in relation to output or cumulative investments, whereas economies of scale relate to production levels during a certain period of time.
These kinds of increasing returns to scale are driven by different forces. Network economies cannot be separated from market shares. They are indeed included as a premise of the model: the value of a product to consumers depends on its market share. By contrast, it is the dimension, or the level of production (not the market share itself) that is the decisive factor in returns to scale. When it comes to learning-by-doing it is experience that counts.
In the economic literature, experience is often measured by cumulative output. Though it is a useful simplification of the model, this approach may be somewhat misleading inasmuch as it suggests that “learning” is a passive activity that occurs automatically when a greater quantity of output is produced. Nothing could be further from the truth. Learning-by-doing necessarily requires investments in data gathering, analysis and testing.
Learning is crucially important to economic progress. However, it does not occur “simply”; it requires investments both at the individual level and at the organizational level as well as at the level of society as a whole. Data gathering is only the first step. To be useful, data needs to be turned into information, knowledge and understanding.
Economies of scale on the supply and demand sides are certainly major economic forces. However, they lose much of their significance in relation to learning-by-doing, which I consider the main source of competitive advantage in technological industries.
SEARCH ENGINES AND ECONOMIES OF SCALE. In view of the above, we may wonder whether or not search engines such as Google, Bing, Yandex and Baidu represent network economies. Do we need to know how many other people use the same search engine as us? Of course not. The important thing is the performance of the search engine itself, not the number of people using it. This means that traditional economies of scale do not apply to search engines.
In the early 2000s there were several general-purpose search engines: Alta Vista, Lycos, Inktomi, Yahoo, Microsoft Live and Google (Lycos, Inktomi and Google stemmed from the NSF/DARPA digital library research program – an initial example of how the funding of government research can contribute to innovation and increase productivity). In those days, people commonly used several search engines. As time went by, some search engines were able to improve their performance, while others lagged behind. There was no apparent advantage due to scale. Indeed, it was often the newest and smallest engine that seemed to work best and to improve most rapidly. This resulted in a consolidation of the sector marked by the presence of a small number of general-purpose search engines.
During this same period of consolidation, we witnessed the emergence of several “special-purpose” search engines for local searches, shopping, travel and so forth. Such search engines tend to focus on commercial considerations – for example, on which areas the most money is in circulation. If we consider commercial searches rather than general purpose searches, the structure of the sector is very different. Some 44% of searches for products start on Amazon, 34% on a search engine and 31% on a specific vendor’s website. This observation is particularly important because the searches most economically advantageous to general purpose search engines are commercial ones, mostly because they attract more advertising. General purpose searches are a particularly difficult area of business because they permit the sale of 6% of what is actually produced (that is, from pay clicks alone). There is fierce competition here, but, as may easily be deduced, they fall short when it comes to producing free clicks.
Though traditional economies of scale on the demand side do not apply to searches, can economies of scale apply on the supply side? Internet multinationals such as Amazon, Google, Facebook, Microsoft and IBM have data centers throughout the world. Many of these companies lease part of their computer and networking infrastructure. This cloud computing technology has the advantage of allowing new players to increase their calculation infrastructure requirements as their operational scale increases. Data centers, which in the past represented a fixed cost, have now become a variable cost, thus generating a considerable increase in income for technological start-ups.
The hardware component of IT now represents a constant return with a view to industrial growth. Clients can order computational power on demand. Providers operating data centers can offer greater power by enhancing the CPU’s core, by increasing the number of CPUs on the motherboard, increasing the number of motherboards on the rack in the data center or even increasing the number of data centers. Each level of increase corresponds to an increase in performance more or less in line with demand.
It is a different matter when it comes to software. Once an investment has been made to develop a piece of software, it can be replicated at almost zero marginal cost. In this regard, software is a perfect example of the learning concept.
INDIRECT NETWORK ECONOMIES. Some observers have said that search engines demonstrate two kinds of network economies, since advertisers want to be where the most users are, and users want to be where the most advertisers are. However, this latter assertion is difficult to confirm in practice, in view of the fact that users generally do not choose a search engine on the basis of the number of advertisements. If anything, given the choice between two search engines, consumers would probably prefer the one with fewer advertisements.
If traditional network economies do not work with search engines, what can indirect economies of scale achieve? This concept implies a somewhat more complex virtuous circle. Let us consider an operating system involving three parts: the vendor of the operating system, the developers of applications for the operating system and the clients that purchase both the operating system and the applications.
Let us assume that two vendors of operating systems are in competition. Application developers may consider this beneficial with a view to creating applications for whatever system has the largest number of users; users, in turn, may consider such an operating system advantageous because it includes a variety of applications. This situation could entail a virtuous cycle: more users means more developers and more developers means more users. The result is a winner-takes-all market, in which the best can capture a very large market share, thereby reducing – if not eliminating – the competition.
Such a model may be attractive, but it does not necessarily correspond to the facts. After all, there are three operating systems for the pc (Linux, Windows and Mac OS), and two main operating systems for mobile devices (iOS and Android). There seems to be room for more than one operating system for both desktops and mobile devices. There appear to be fewer indirect network economies than is commonly thought. Indeed, application developers are involved on several platforms and can offer applications for both main operating systems for mobile devices.
THE VALUE OF KNOWLEDGE. One variation on the theme that we have been considering concerns so-called “data entry barriers”. The idea is that a major player already working in the sector (an incumbent) has a larger quantity of data from its users, which enables it to develop better products than its potential competitors, thus granting it an unbeatable competitive edge.
The first and most obvious point is that if there is a data barrier to entry, it applies to all industries. After all, players already involved in the sector do indeed produce a good or a service, unlike newcomers. So by definition incumbents must have more data than new players. Thousands of new companies are formed every year and the fact that they have less data than their established competitors does not seem to discourage them in the least.
But is starting a new business a matter of data or knowledge? For instance, if I wanted to enter the car manufacturing industry but knew absolutely nothing about how to build a car, should this be regarded as a barrier to entry?
Knowledge is a crucial part of production. In economic models, knowledge is embodied in the production function, but in the real world it is embodied in people. If you want to launch a car company but know nothing about how to build a car, the first thing you would have to do is to hire car engineers having the necessary expertise.
In the search engines sector, new competitors – who may have started trading without any data – have often successfully competed with players already established in the market. Google was not the first search engine, but it had a better algorithm than other existing players. Furthermore, it succeeded in building a learning system that constantly improves on the basis of the initial algorithm.
When they entered the market, the companies that are now successful did not have the same data that they have now, but they were still able to acquire sufficient initial expertise and to gather sufficient data, information and expertise to gain a competitive advantage over players already in the market.
It is enough to consider, for instance, the way in which Google gained experience in the voice recognition sector in 2006. The first thing it did was to hire top researchers in the field, who are the ones that supplied Google with its knowledge. These researchers developed GOOG-411, a service that used voice recognition for phone directory services. The team’s key intuition was to implement the voice recognition algorithm in the cloud rather than on individual devices; and this enabled the algorithm to learn – literally – from millions of verbal requests. Within the space of a few months, the algorithm became very good, and by the end of the year it was one of the best voice recognition systems available. Some years later, the Google Brain teams were able to apply neural networks to criticalities relating to voice recognition and thus to improve performance further.
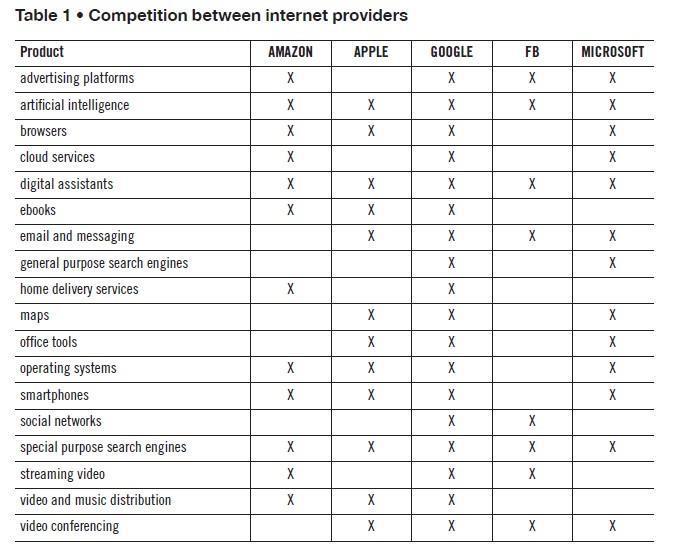
Table 1 – Competition between internet providers
However, other companies, too, are implementing similar improvements. Amazon has developed Echo and has set itself the target of recognizing and answering voice requests more quickly than has been possible hitherto. When Echo was first developed, the average response time was about 2.5-3 seconds. The working team set itself a target of 2 seconds. But that was not good enough for Jeff Bezos, who called for a latency of just 1 second. This target has yet to be achieved, but they have managed a latency of as little as 1.5 seconds, which is better than any other technology available at the present time.
INVESTING IN EXPERTISE AND KNOWLEDGE. I have described three concepts: network economies, returns on scale and learning-by-doing. Network economies are a demand-side phenomenon (the value depends on sharing), whereas the other two effects are supply-side phenomena (the cost depends on current or cumulative output).
If we consider the leading high-tech companies of today, we see strong competition. As the table shows, they are all competing in several different sectors. This competition is the reason why we can see such rapid innovation and such low costs in the technology industries.
All these companies invest heavily in expertise. At any particular moment, they may have different capabilities, but they can overcome shortcomings by learning quickly. At one time, Google did not know much about operating systems or voice recognition, Facebook knew little about video streaming and image searches and Amazon knew little about selling cloud computing. But they learned fast and the knowledge that they accumulated is the key reason for their competitive advantage in online industries.
The opinions expressed are exclusively those of the author and do not necessarily reflect Google’s opinions.